
«« 「ガラスの花と壊す世界」はやっぱりリモの可愛嫁力が見どころでした(少しネタバレ) | queryfeedを使ってブログに独自のTwitter掲載情報を掲載しよう »»
ブログ本文の単語分析をPHPのみでexecとか外部APIとかなしで実装できないか?
2016年1月24日
個人的に自家製botづくりに興味が有る今日このごろ。
そこで気になるのが、botでサイトの巡回をするのはいいけど、HTMLのうちどの辺が本文で、その本文が何が書いてあったのかというのをどのように機械的に分析させるのか?
まあかなり抜け穴がありそうですけど、ざっと考えるなら、
1.HTMLの中で文章が多そうな部分を抽出し
↓
2.接続詞を除去して
↓
3.アルファベット・カタカナ・ひらがな・漢字が変わっているところは別の単語としてカウントし
↓
4.集計して単語の数が多いものについて、このページはその単語のテーマについて語っていると判断してみる。
というのはどうでしょう。
しかし、自分でコードを考え試行錯誤するのが面倒くさいなぁ。
できれば、共有サーバーなので、PHP上で動作し、なんかインストールする必要がなくて、あと外部サービスはいきなり使えなくなることも有りますから使わなくて済むならそっちがいいな。
という条件で先人の知恵はないものか?とGoogle大先生に聞いてみたところ、それぞれすでにやっぱり存在しました。
情報公開してくれた作者の方&Google大先生ありがとうございます。
○1番について
http://blog.zuzara.com/2006/06/06/84/
ブログの記事本文を抽出するスクリプトをつくってみた - zuzara
○2番と3番について
http://neoinspire.net/archives/61
PHPでブログのキーワードを抽出するクラス - Neo Inspiration
○4番について
流石にここぐらいは自分で組んだ。
これらのコードを組み合わせて、試しに自分の過去記事についてデスクトップ上から調べさせてみたところ、なんかそれっぽい結果が出てきた!
https://kuje.kousakusyo.info/tsunezune/archives/2016/01/
000614garakowa.shtml
「ガラスの花と壊す世界」はやっぱりリモの可愛嫁力が見どころでした(少しネタバレ) : つねづね思ふこと 〜 ゲームやアニメの紹介を中心に、あと気がついたときにプログラムネタも書いてます
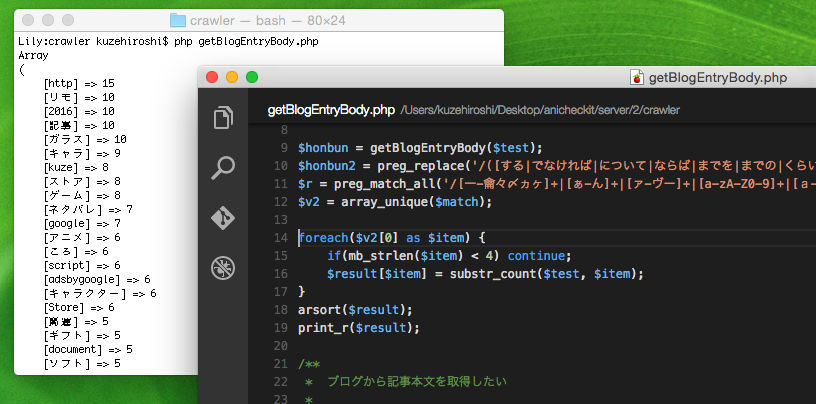
このページの場合、上位の単語は以下のとおり。
[http] => 15
[リモ] => 10
[2016] => 10
[記事] => 10
[ガラス] => 10
[キャラ] => 9
ノイズを除去する必要はありますが、「リモ」の「キャラ」を押していたのは確か。
その意味ではこの分析方法はいい線いっているので使えるかも。
ただ「ガラスの花と壊す世界」については...色々検証中「文字数の少ない単語は無視する」というルールを入れたせいか、「花」と「壊す」と「世界」は無視して「ガラス」のみしか拾わなくなった(なら何故「リモ」は拾えたんだろう?)ので、この辺もう少し上手く認識させるには調整と工夫が必要ですね。
自分のサイトばかりではなく、ほかのサイトに対しても同様の処理を動かしてみました。
http://anime.eiga.com/news/101858/
「ガラ壊」花守ゆみりに種田梨沙、佐倉綾音、茅野愛衣ら"先輩"がデレデレ : ニュース - アニメハック
[アニメ] => 20
[Check] => 15
[花守] => 14
[ガラ] => 11
[世界] => 10
[佐倉] => 10
「花守」とは、「ガラスの花と壊す世界」でメインヒロインのリモ役を担当した声優「花守ゆみり」の苗字。
同じテーマ「ガラスの花と壊す世界」を扱っている記事なのに「ガラス」がトップに出てこなかったのは、記事のタイトルが「ガラ壊」と略字を使ったからか。
どちらにせよこのままでは連想配列的には一致がないので、どちらも「ガラスの花と壊す世界」であるとして登録はできないな...もう一捻り必要か?
例えば、先ほどのアニメハックの場合も、metaタグのkeywordsには「ガラスの花と壊す世界」が存在するから、そちらの方で共通性を見出させるようにする?とか。
あとは更にこれらの処理を加えて、クローラーとして稼働できるようにする予定です。
・HTML解析結果をMySQLに格納させる処理を書く
・実際にbotとしてネットを徘徊させるルーチンとか(その際に提供元から嫌われないようおとなしく行う)
とりあえずは、RSSをいくつか指定して、それらを定期循環させるようにしよう。
・逆に分析結果をMySQLから呼び出すAPI
・需要がなさそうな情報や古い記事を自動除去のルーチン
・これらをできるだけ低負荷で動かす(共用サーバーだしね)
うーん、まだまだ完成まで先はまだまだ長そうだ。

SBクリエイティブ
売り上げランキング: 90,857
【余談】
↑のAmazonリンクについて自分も買ってみて、なる程10分で簡単なクローラーが作れるんだ!という簡単そうなところからスタートするのは良いのですが、主に使っているのがやっぱり「Ruby」とか「シェルコマンドのWgetコマンド」とかを使っているので、レンタルサーバー上で動かすには前提が厳しい物もあるので、やっぱり自分の解釈力が試されます。
投稿者 kuze : 2016年1月24日 23:57
- API『call_picture_from_amazon』について、PA-APIが無効化されてもキャッシュから商品画像URLを返せるバージョンを公開しました(2019/07/10更新)
- 「ガラスの花と壊す世界」はやっぱりリモの可愛嫁力が見どころでした(少しネタバレ)
- 連想配列と総量計算
- 連想配列(ハッシュ)はやはり使える!
- 手作り省エネデジタルフォトフレームの作り方が気になる
- Python3.4向けにつくったAPIが、Python3.6では動かなくなったので直してみた
- Windows 10 HomeやProfessionalにおいて行う設定やインストールしたいソフトをまとめてGithub Pagesにまとめてみた
- Office Lensで素早くその場で名刺や原稿などをスキャン!
- Amazon商品をより魅力的に紹介できるAmaQuickをテンプレート例とともに紹介してみた
«« 「ガラスの花と壊す世界」はやっぱりリモの可愛嫁力が見どころでした(少しネタバレ) | queryfeedを使ってブログに独自のTwitter掲載情報を掲載しよう »»
主にiPhoneアプリの紹介やWeb開発などのPC系の話題と、アニメやゲームなどのサブカルな話題を取り扱っています。
- アニメ・コミック・ライトノベル [167 記事]
- ゲーム [80 記事]
- ドラマ等 その他の番組 [18 記事]
- 実用ソフト&サイト [244 記事]
- 特撮 [24 記事]
- 社会情勢 [84 記事]
- 身の回り [181 記事]
- 映画『ゴジラ-1.0』レビュー(ネタばれあり)
- Three-up HC-T2206WHで狭い部屋も快適に
- 「君たちはどう生きるか」は父親を気にするかで評価が別れそう(ネタバレあり)
- 画像生成AIソフトでしばらく毎日SNSに画像を上げてみたけどネタ出しについて
- ホットクックを使えば一人で並行して色々作りやすくなるのでオススメ












更新情報はRSSをご利用下さい
コメント